Confusing or misunderstood topics in systems programming: Part 1


Threads and the general concept of concurrency are among the most widely misunderstood and confusing topics for newer developers. This is partially due to popular language features that abstract away the details, leaving many developers with a lack of understanding of the underlying concepts. This series is meant to help clarify some of these concepts and provide a better understanding of how they work.
First let’s just be sure we all understand what concurrency is (as it if often confused with parallelism):
Concurrency is the ability of different tasks, parts or units of a program or algorithm to be executed in overlapping periods, out of order or in partial order, without affecting the final outcome.
Parallelism is a specific type of concurrency, where multiple tasks are executed ‘in parallel’, simultaneously on separate CPU cores. We will not be discussing parallelism in this series.
First let’s make some clear distinctions so we have the correct terminology for the rest of the series. There are many ways to refer to, and in fact, even many ways to think about threads.
Hardware threads are physical resources provided by the CPU, with typically two threads per core. This is not what we will be discussing in this post.
We will be discussing Software threads in this series, which are a construct provided either directly by the operating system (We will refer to these from now on as native threads), or they are provided by a program running in user-space, and we will refer to these as virtual threads.
In the context of software threads, either type can essentially be described as
A task, or 'sequence of instructions' that can be scheduled for independent execution.
This is why you may sometimes hear them be referred to as tasks.
‘virtual’ (non-native) threads can also sometimes be called ‘green threads’, ‘fibers’, ‘coroutines’, ‘tasks’, ‘goroutines’, ‘lightweight threads’, and probably many more names I am not aware of. But we will be referring to them as ‘virtual threads’ for the rest of this series.
Here is a brief comparison of the two:
Note: This is a simplification and there are many more differences, but this is a good starting point. There are some general disputes about the efficiency of certain types of virtual threads, but this is largely implementation specific as there are many different ways to implement them.
| Native threads | Virtual threads |
|---|---|
| The OS schedules and manages these threads. | The OS is not aware of these threads, they are managed by a library or runtime. |
| These threads are typically slower to create and manage. | These threads are typically faster to create and manage. |
| These threads are more expensive in terms of resources. | These threads are less expensive in terms of resources. |
| These threads are more stable and reliable. | These threads are less stable and reliable. |
For context let’s also define some other terms we will be using throughout this series:
runtime or async runtime - In this context, we are talking about a library, framework or language feature that provides scheduling of virtual threads for execution, and handle the scheduling of many virtual threads as to have them run concurrently.
A runtime can be thought of as a layer of software that sits above the operating system, running along-side our code (as the same process, either kind of bundled with our code by the compiler or in the case of JS, our code being ran by the interpreter/runtime), and can be responsible for many different things during our code’s execution.
If you aren’t familiar already with what they are, you still may have heard of nodejs, bun, and deno being Javascript runtimes.
The engines that are responsible for JIT compiling and executing JS code are actually V8 (Chrome) for node and deno and WebKit (Safari) for bun. So what is node or bun doing then, if chrome is being used as the engine?
Because chrome and safari execute JS in a sandboxed environment, they have their own runtimes that are responsible for scheduling tasks which execute on different threads so as not to block rendering of the DOM, and also for handling things like garbage collection.
In order to execute JS code outside of the browser, you need a runtime to handle these things and provide an interface for things like I/O that are not handled by the browser or the engine itself, as they are not part of the ECMA script standard. But that is a topic for another day.
You have runtimes that are responsible for things like garbage collection or reference counting (which is technically a lightweight form of garbage collection). These always ship with the language itself, and are internal to the language’s implementation.
There are also runtimes like we are discussing, which provide asynchronous scheduling of tasks in our program. These can be provided by the language,(and could do both garbage collection and scheduling of tasks). But they can also be provided by a third party library or framework. (GUI libraries, web servers, etc.)
The JVM and the python interpreter are other examples of languages that have a runtime that handles garbage collection and async scheduling.
The most common interface for spawning native threads on unix systems is the pthread C library. This library is most commonly used in low level languages like C and C++ directly, and it’s used under the hood in Rust’s standard library as well.
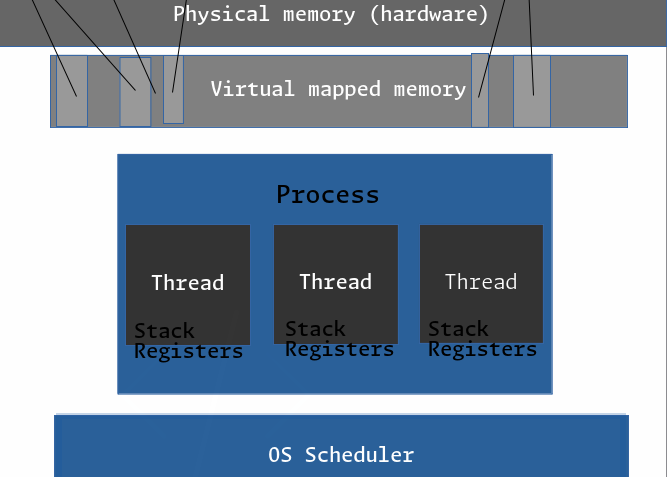
When you spawn a new native thread in your C program, you are telling the kernel to create a new task within the process space of your program. This new thread will have it’s own stack, and will be handled and scheduled by the kernel alongside the other threads in your process. It will also have access to the same heap memory and global variables as the other threads in your process.
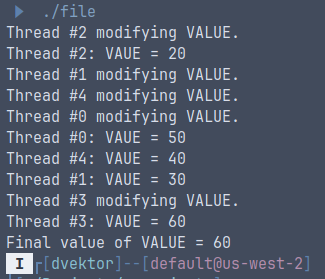
This is a simple example of a C program that will spawn some threads and modify a global variable, printing the order and the value:
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
// note: you wouldn't want to write code like this in a real program for MANY
// reasons, some that will be discussed later
int VALUE = 10;
// Thread function to modify and print the global variable
void *modify_and_print_value(void *threadid) {
long tid = (long)threadid;
// We are passing the thread id as void*, so it must be cast to the proper type.
// typically we would pass a pointer to a struct with the thread id and any other data we
// need to pass to the thread
// then we are printing the thread id and the current value of the variable
printf("Thread #%ld modifying VALUE.\n", tid);
VALUE += 10; // Modifying the global variable
printf("Thread #%ld: VAUE = %d\n", tid, VALUE);
pthread_exit(NULL);
}
int main() {
int thread_count = 5;
pthread_t threads[thread_count]; // initialize an array of threads
int rc; // return code
long tid; // thread id
// Create threads one at a time, pass in the thread id and the function to call
for (tid = 0; tid < thread_count; tid++) {
rc = pthread_create(&threads[tid], NULL, modify_and_print_value,
(void *)tid);
if (rc) {
// if there is a return code from pthread_create, print an error and exit
printf("ERROR; return code from pthread_create() is %d\n", rc);
exit(-1);
}
}
// Wait for the threads to complete
for (tid = 0; tid < thread_count; tid++) {
pthread_join(threads[tid], NULL);
}
printf("Final value of VALUE = %d\n", VALUE);
pthread_exit(NULL);
}

(The challenges that come along with this, and how we work around them will be discussed in the next post)
Relative to the last post where we discussed processes and context switching, a native thread can be thought about like a kind of “sub-process”. A process can have multiple threads, and each thread has it’s own stack. Each thread owned by a process shares the same virtual memory space as all the other threads owned by that process. This is why we can modify a global variable or access memory allocated on the heap from any thread in the process.
If we remember, the process control block contained a pointer to thread_info, this is because a thread is the same as a process as far as execution by the OS is concerned. In fact, the task_struct we looked at in the previous post was actually a per-thread implementation, as the OS looks at processes and threads simply as ‘tasks’ to be scheduled and executed. This is indeed kind of obvious when we consider that processes often have just one thread.
The reason we say that native threads are typically slower and more expensive is because they require a context switch. A context switch between threads in the same process is faster than a context switch between processes, but it is still a non-trivial operation relative to switching between virtual threads in a runtime.
Generally speaking, the main difference between virtual and native threads is who is responsible for scheduling them. Let’s switch to some code we maybe are used to seeing in a language like Javascript. (I know, gross):
function someAsyncFunction() {
let result = fetch('https://ifconfig.me', { method: 'GET' });
return result;
}
async function main() {
let result = await someAsyncFunction();
if (result.ok) {
await result.text().then((text) => {
console.log(text);
});
}
}
So why do we need Async here, not just the keyword, but the entire concept?
Well let’s think about what is happening. When we call someAsyncFunction we are making a network request via the fetch function.
This network request, in CPU-time, will take approximately half an eternity. If we simply call this function, the program will simply be executing, doing nothing for up to a few hundred milliseconds blocking the current thread while it waits for the network request to complete. The CPU would be able to execute literally thousands of instructions in that amount of time.
The operating system will not necessarily be aware of this to the point where it will be able to automatically schedule other threads to run while the network request is happening.
So, from what we know so far, what would we do to improve this? Do we spawn a native thread and make the network request on that separate thread in our process, giving up control to the OS scheduler to now handle the two tasks in our processes?
It is very common for languages or libraries to implement an async runtime that can handle the scheduling of the network request on a separate virtual thread, and then resume the main thread when the network request is complete. There would be no context switch necessary between tasks, and the OS would be none the wiser.
This design isn’t without flaws and depending on what other tasks our program is waiting to be execute along with some other variables and implementation details, will all determine whether we will gain much benefit from concurrency. But how does it work?
At the heart of every async runtime is what’s known as an event loop. This is an infinite loop that is responsible for scheduling tasks, polling existing tasks for completion, checking for IO events, executing callback functions, and more. Many libraries such as GUI libraries and web servers use their own event loops, and implementations can vary whether the tasks are IO bound or CPU bound.
Some runtimes operate entirely on a single thread (nodejs) and some have the ability to operate across multiple native threads (the Tokio library for Rust), but what they all have in common is that they provide an abstraction for the developer to work with asynchronous tasks by scheduling many virtual threads in place of the OS scheduler.
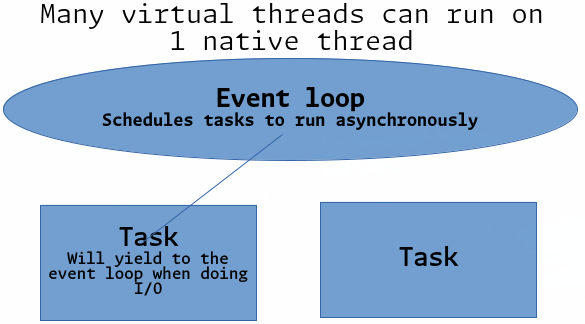
When you make the call to fetch, the event loop will realize that this is a blocking operation, and the virtual thread will yield control to the main event loop, which will essentially schedule the other functions capable of running to completion, only to return to the fetch request to complete at a time when it’s not blocking any other tasks.
There are many examples of these problems we developers have, that translate very well to this particular abstraction. When we have a webserver serving thousands of HTTP requests, it makes perfect sense to us, to pass off each request to a separate ‘thread’ or ‘task’ to be handled individually, with the hope that any blocking operations can be scheduled at an optimal time. This is the same concept, just applied to a different problem.
In reality, especially when you’re receiving hundreds or thousands of request per second, you wouldn’t want to spawn a new OS thread for every request, as this would be very inefficient. It only makes sense to developers that we have this very concrete way of thinking about a task, and each task is handled by a separate ‘thread’.
As developers, we want to be able to return something from a function that will resolve to some type/value at some point eventually, as this is a very simple way of thinking about the problem.
This is why asynchronous runtimes are so powerful, they provide a very useful abstraction and give us a simple and idiomatic way of thinking about concurrency, allowing us to write code that is fairly easy to reason about, and is also efficient.
Where they fall short, is in the fact that they are not as stable, not as powerful, and are not as well suited to certain types of problems as native threads.
One thing we must remember, is that the operating itself can be thought about as a global runtime, with the kernel’s scheduler being replaced by the event loop of the async runtime. Any time we build another abstraction, at each layer we are adding overhead, we are losing some connection and understanding of the underlying system, and we are adding complexity. This is why it is important to understand the underlying concepts, and to understand the trade-offs of using these abstractions.
In the next post, we will discuss native threads in greater detail, look at some implementations and see what kinds of problems they are best suited to solve. And we will look at the challenges and drawbacks of concurrency in general, and look at how some of those challenges are solved.
We’ll also be looking at how threads access shared resources, and what some of the tools are that are used to solve the difficult problems that arise when working with threads. Particularly we’ll be checking out a couple newer concepts featured in Rust, and we’ll discuss how functional languages have been solving difficult concurrency issues for many years now.
It’s likely this series on threads and concurrency will be 4 or 5 parts, because I would like to break them into fairly manageable chunks. It’s a lot of information, and I want to make sure newer developers can follow along.
Now that we have a good introduction to the concepts, we can start to get into the nitty gritty details. Maybe at the end of this we can even write a basic scheduler or a simple event loop for an async runtime.
The next post should be much more in depth, as I want to give some real world examples of multi-threaded C programs, and task about the challenges and solutions to those problems.
I find it important to try to understand the abstraction layer below the one I am working with, and to understand the trade-offs of using that abstraction. This is part of why I am writing this series, and I hope to provide some clarity to those who are confused or intimidated by this topic.
I hope someone found this post useful, as always if you believe I have made a mistake or have any feedback, please let me know!
Processes, Pipes, I/O, Files and Threads/Async
My story, and how this is all possible
Unsolicited advice for anyone seeking to learn computer science or software development in 2023.
How I got here is already far too long, so I must include a separate post for all the credits and gratitude I need to extend to those who made this possible.
Following up on the first impressions post, let’s solve a problem in OCaml and compare the Rust solution.
Humorous article, completely unrelated to, and written before, the others ended up actually on the front page.
OCaml: First impressions